

Por Mariëtte Le Roux
O computador que surpreendeu a humanidade vencendo os melhores jogadores mortais em um jogo de tabuleiro de estratégia que exige "intuição" se tornou ainda mais inteligente, disseram seus fabricantes. A versão atualizada do AlphaGo é totalmente autodidata - um passo importante em direção ao surgimento de máquinas que alcancem habilidades sobre-humanas "sem nenhuma contribuição humana", relataram no jornal científico Nature.
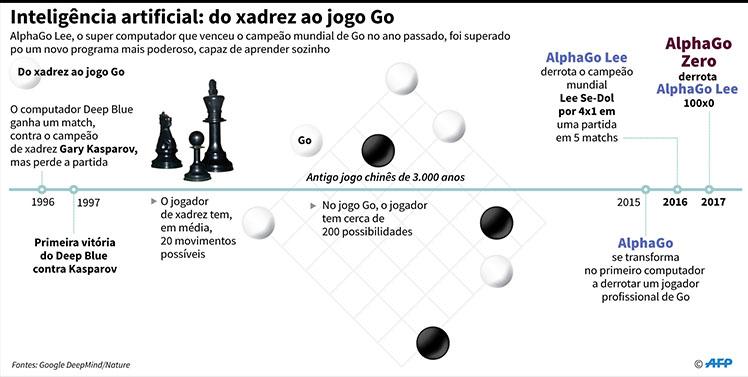
O sistema de Inteligência Artificial (IA) batizado de AlphaGo Zero aprendeu sozinho, em alguns dias, a dominar o jogo de tabuleiro chinês conhecido como "Go" - considerado o desafio entre duas pessoas mais complexo já criado. Ele inventou seus próprios movimentos originais para eclipsar toda a perspicácia que os humanos adquiriram no Go ao longo de milhares de anos.
Depois de apenas três dias de autotreinamento, a máquina foi testada contra o AlphaGo, seu precursor que anteriormente destronou os principais campeões humanos. O AlphaGo Zero venceu por 100 partidas a zero.
Leia mais
Computador derrota jovem gênio chinês em partida de Go
Inteligência artificial entra aos poucos na vida cotidiana
"O AlphaGo Zero não só redescobriu os padrões e as aberturas comuns que os seres humanos tendem a jogar... ele acabou vencendo-os com preferência pelas suas próprias variantes que os humanos sequer conhecem nem jogam no momento", disse David Silver, pesquisador principal do AlphaGo.
O jogo chinês de 3.000 anos jogado com pedras pretas e brancas em um tabuleiro tem mais configurações de movimento possíveis do que a quantidade de átomos no universo. O AlphaGo ganhou as manchetes mundiais em março de 2016 com sua vitória por 4-1 sobre o 18 vezes campeão de Go Lee Se-Dol.
A derrota de Lee mostrou que a IA estava progredindo mais rápido do que se pensava, disseram especialistas na época, que pediram normas para garantir que a IA permaneça sempre sob controle humano. Em maio deste ano, o programa atualizado AlphaGo Master venceu o campeão mundial Ke Jie em três de três partidas.
- Não limitado por humanos -
Ao contrário de seus predecessores, que treinaram com dados de milhares de jogos humanos antes de praticar, o AlphaGo Zero não aprendeu com os humanos, nem jogando contra eles, de acordo com pesquisadores da DeepMind, a empresa britânica de inteligência artificial que desenvolve o sistema, adquirida pela Google.
"Foi dito a todas as versões anteriores do AlphaGo: 'Bem, nesta posição o especialista humano jogou este movimento particular, e nesta outra posição o especialista humano jogou aqui'", disse Silver em um vídeo explicando o avanço.
O AlphaGo Zero pulou este passo. Em vez disso, foi programado para responder a uma recompensa - um ponto positivo para cada vitória versus um ponto negativo para cada perda. Partindo apenas das regras do Go e sem instruções, o sistema aprendeu o jogo, elaborou uma estratégia e melhorou enquanto competia contra si mesmo - começando com um "jogo completamente aleatório" para descobrir como a recompensa é ganha.
Este é um processo de tentativa e erro conhecido como "aprendizagem por reforço". Ao contrário de seus predecessores, o AlphaGo Zero "não está mais restringido pelos limites do conhecimento humano", escreveram Silver e o CEO da DeepMind, Demis Hassabis, em um blog.
Surpreendentemente, o AlphaGo Zero usou uma única máquina - uma "rede neural" que imita o cérebro humano - em comparação com o "cérebro" de múltiplas máquinas que venceu Lee. Os descobertas sugeriram que a IA baseada na aprendizagem por reforço tem um melhor desempenho do que aquelas que dependem do conhecimento humano, disse Satinder Singh, da Universidade de Michigan, em um comentário também publicado pela Nature.
"No entanto, este não é o começo de qualquer fim porque o AlphaGo Zero, como todas as outras IA bem-sucedidas até agora, é extremamente limitado ao que sabe e ao que pode fazer em comparação com humanos e até com outros animais", afirmou.
A habilidade do AlphaGo Zero para aprender por conta própria "pode ??parecer assustadoramente autônoma", disse Anders Sandberg, da Universidade de Oxford. Mas há uma diferença importante "entre a inteligência polivalente que os humanos têm e a inteligência especializada" do software de computador, disse Sandberg à AFP.
"O que a DeepMind demonstrou nos últimos anos é que é possível fazer softwares que podem ser transformados em especialistas em diferentes domínios... mas eles não se tornam inteligentes de modo geral".
